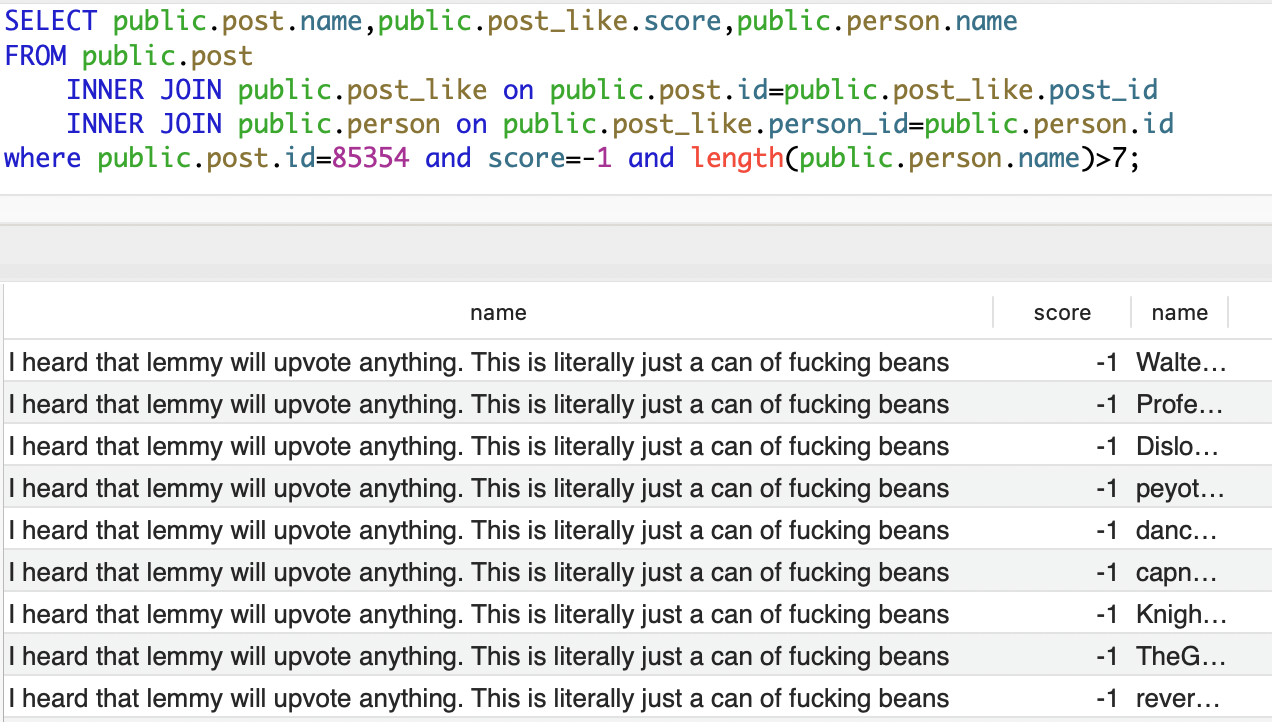
Edit: obligatory explanation (thanks mods for squaring me away)… What you see
via the UI isn’t “all that exists”. Unlike Reddit, where everything is a black
box, there are a lot more eyeballs who can see “under the hood”. Any instance
admin, proper or rogue, gets a ton of information that users won’t normally see.
The attached example demonstrates that while users will only see upvote/downvote
tallies, admins can see who actually performed those actions. Edit: To clarify,
not just YOUR instance admin gets this info. This is ANY instance admin across
the Fediverse.
Un exemple sur Kbin, on peut voir les deux personnes qui ont downvotes : https://kbin.social/m/dach@feddit.de/t/168422/Bier-ohne-Alkohol-wird-zum-Massengetrank/votes/down
En fait, je voyais le chiffrement au niveau du serveur et pas tant au niveau de la communication. Si on entre dans le serveur, tous les fichiers seraient chiffrés. Et on pourrait pas prendre tout le contenu sans posséder les clef de l’admin et donc cela bloquerait les robots.
Apres si on lit publiquement le contenu alors le robot peut le lire ? Est ce que ça protegerait aussi nos ID ou c’est autre chose ? Enfin, je crois que j’ai besoin de documentation. J’atteins mes limites en tant que sysop amateur.
Quel serait l’intérêt de chiffrer des données qui sont accessibles via le site ? Lemmy, 99% des données, ce sont les fils et les commentaires.
Certaines données devraient être chiffrées (comme les adresses e-mail des utilisateurs, mais sur pas mal d’instances elles sont facultatives). Les mots de passe sont normalement gérés par de hashes avec des salt, donc impossible de retrouver le mot de passe sur base du hash.
D’accord, mais pourquoi est-ce que les robots iraient récupérer nos données sur le serveur, alors qu’ils peuvent simplement parcourir le site Lemmy et tout copier?
Justement c’est surement parce que je connais pas l’aspect technique et donc si tu as des ressources à me recommander, je veux bien. Dans ma tete, le robot et l’utilisateur n’utilisent pas les meme canaux pour recuperer et lire le contenu. Ca vient du fait que si j’utilise sftp pour recuperer les données de mon nuage et bien sans mes ID, c’est impossible de les lire. Si j’utilise un client et que je me connecte avec mes ID, alors je peux les lire.
En fait la différence principale c’est qu’ici, les messages sont accessibles via le site, en HTTP, par tout le monde, là où ton serveur SFTP ne l’est pas.
Si quelqu’un demain décide de récupérer tous mes commentaires sur Lemmy, il n’a qu’à aller sur mon profil et copier les messages.


je connais très mal le sujet.
En fait, je voyais le chiffrement au niveau du serveur et pas tant au niveau de la communication. Si on entre dans le serveur, tous les fichiers seraient chiffrés. Et on pourrait pas prendre tout le contenu sans posséder les clef de l’admin et donc cela bloquerait les robots.
Apres si on lit publiquement le contenu alors le robot peut le lire ? Est ce que ça protegerait aussi nos ID ou c’est autre chose ? Enfin, je crois que j’ai besoin de documentation. J’atteins mes limites en tant que sysop amateur.
Quel serait l’intérêt de chiffrer des données qui sont accessibles via le site ? Lemmy, 99% des données, ce sont les fils et les commentaires.
Certaines données devraient être chiffrées (comme les adresses e-mail des utilisateurs, mais sur pas mal d’instances elles sont facultatives). Les mots de passe sont normalement gérés par de hashes avec des salt, donc impossible de retrouver le mot de passe sur base du hash.
Empecher les robots de recupérer nos données ? Le web scrapping par exemple ? Mais je sais pas techniqaement comment ça fonctionne.
Je me dis, ce que je lis est en clair car dechiffré au niveau du client et le reste des transit, stockage est inaccessible aux robots car chiffré.
D’accord, mais pourquoi est-ce que les robots iraient récupérer nos données sur le serveur, alors qu’ils peuvent simplement parcourir le site Lemmy et tout copier?
Justement c’est surement parce que je connais pas l’aspect technique et donc si tu as des ressources à me recommander, je veux bien. Dans ma tete, le robot et l’utilisateur n’utilisent pas les meme canaux pour recuperer et lire le contenu. Ca vient du fait que si j’utilise sftp pour recuperer les données de mon nuage et bien sans mes ID, c’est impossible de les lire. Si j’utilise un client et que je me connecte avec mes ID, alors je peux les lire.
Et donc j’imaginais un truc comme ça.
En fait la différence principale c’est qu’ici, les messages sont accessibles via le site, en HTTP, par tout le monde, là où ton serveur SFTP ne l’est pas.
Si quelqu’un demain décide de récupérer tous mes commentaires sur Lemmy, il n’a qu’à aller sur mon profil et copier les messages.
Je ne sais pas si c’est plus clair ?
Oui effectivement c’est plus clair. Je vais réviser un peu les protocoles du coup et trouver de quoi comprendre comment le web scrapping marche.